UCI Mission Copilot Demo¶
An AI-augmented counter-UAS mission copilot built on the U.S. Air Force's Universal Command and Control Interface (UCI) v2.5 standard.
Status: Phase 0 SBIR D2P2 prior-art sprint — game-theoretic counter-UAS solver shipping end-to-end. OS-MCCFR + RM+ kernel (
@uci-demo/solver) trained continuously by a headless daemon against the full-depth tactical game (@uci-demo/game); blueprint retained onuci-demo/solver/blueprint;SolverAgentconsumes it at decision time. Bayesian identity belief mirror per track; 9-term zero-sum payoff with version-tagged invariants; 8 doctrinal subroutines composing the strategy bank with the regret-table average strategy. Bus-symmetric Red service via the bridge pattern (scripted backend; solver-driven backend stubbed). Kuhn correctness gate at <0.01 exploitability for ES-MCCFR / 10k iter; <0.05 for OS-MCCFR / 20M iter.All v1.3 capability surface is intact on top of this: full counter-UAS arc end-to-end on 21 of 596 UCI v2.5 message types, doctrinal approval round-trip, engagement lifecycle, fuel-driven contingency, operator mid-engagement cancel, capability advertisements + on-wire coverage polygons at boot, drone-model classification, post-engagement assessment, operator MODIFY round-trip. Three scenarios in the library (Tripwire, Vanguard, Stillwater). Solver runs on commodity CPU; no GPU dependency, no neural networks. Real Claude in the loop on the LLM path or scripted fallback when neither solver nor LLM is configured.
📖 Docs site: uci-docs.shebash.dev —
this README, the 10 design memos, and the SBIR proposal materials,
rendered with sidebar navigation + search + syntax highlighting.
What this is¶
A demonstration that the UCI v2.5 standard — which ships as XSDs + a normalized interface spec but no reference software ("hello world… forthcoming," per the upstream README) — is enough to run a real counter-UAS mission with an AI copilot in the loop.
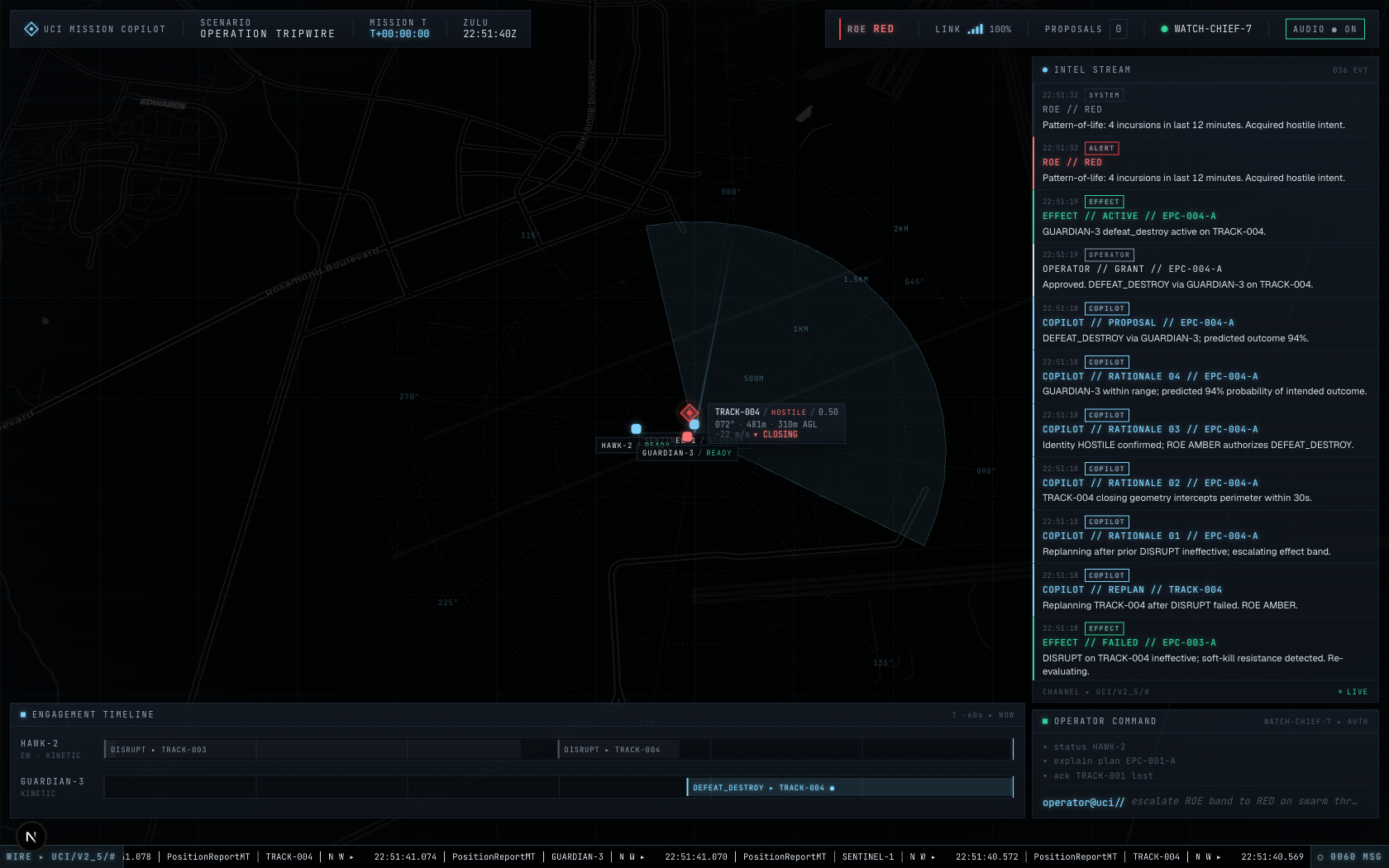
The headline scenario is Operation Tripwire: a forward operating
base under small-UAS incursion, defended by a sensor tower, an EW
quadcopter, and a kinetic effector. A Claude-powered (or
deterministic-fallback) agent watches the bus, proposes effects on
schema-compliant EffectPlanCommandMT messages, and the operator
approves, modifies, or denies via the standard's own
EffectExecutionApprovalStatusMT. Resilient targets force the agent
to escalate from soft-kill to kinetic; ROE band shifts colour the
agent's posture in real time. Two companion scenarios stress the same
copilot under swarm saturation (Vanguard) and dense friendly airspace
(Stillwater).
Algorithms & math¶
This section documents the algorithmic stack shipped across the Phase
0 sprint. Each subsystem ships with a design memo in plan/;
this is the executive summary with the math made explicit.
Three packages + one service form the layer:
@uci-demo/game— pure domain types: game state, dynamics, Bayesian identity belief, payoff, infoset hash, world-mirror projection. No solver, no MQTT.@uci-demo/solver— ES-MCCFR + OS-MCCFR kernel, regret + average-strategy tables, 8 doctrinal subroutines, strategy bank, blueprint serializer.services/solver-daemon— headless self-play loop; publishes the trained policy on the bus.services/copilot— consumes the blueprint at decision time via theSolverAgentpath.
Three version constants protect cache invariants across the layer:
BELIEF_V = 1 (@uci-demo/game/belief.ts), PAYOFF_V = 2
(@uci-demo/game/payoff.ts), INFOSET_V = 1
(@uci-demo/game/hash.ts). Plus SCHEMA_VERSION = 2 on the
serialized blueprint envelope (@uci-demo/solver/serialize.ts). Any
reweighting bumps the relevant constant; deserializers refuse
mismatched payloads outright.
1. Bayesian identity belief¶
Every track on the wire is described by EntityNotificationMT.Severity
(four-state ladder) and optionally EntityMT.Identity.Platform.ThreatType
+ Confidence. The agent's question: given those noisy observations,
what is the posterior over the six UCI identity enum values?
Standard Bayesian update. For a track with prior \(P(i)\) over the
identity set \(\mathcal{I}\) (the six UCI identity enum values:
UNKNOWN, ASSUMED_FRIEND, FRIEND, NEUTRAL, SUSPECT, HOSTILE)
and observation \(o\):
updateIdentityBelief(prior, obs) in
packages/uci-game/src/belief.ts
is the implementation. Pure function; no I/O. Returns the prior
unchanged if every product clips to zero (degenerate likelihood guard).
First-contact prior. A non-flat prior tilted toward "I don't know yet" — most aerial contacts are not engaged before some classification arrives:
| Identity | \(P(i)\) |
|---|---|
| UNKNOWN | 0.30 |
| ASSUMED_FRIEND | 0.15 |
| FRIEND | 0.10 |
| NEUTRAL | 0.10 |
| SUSPECT | 0.20 |
| HOSTILE | 0.15 |
Severity likelihood matrix. Rows sum to 1.
| INFORMATIONAL | ADVISORY | CAUTION | WARNING | |
|---|---|---|---|---|
| UNKNOWN | 0.05 | 0.15 | 0.60 | 0.20 |
| ASSUMED_FRIEND | 0.10 | 0.70 | 0.18 | 0.02 |
| FRIEND | 0.15 | 0.80 | 0.04 | 0.01 |
| NEUTRAL | 0.10 | 0.65 | 0.20 | 0.05 |
| SUSPECT | 0.03 | 0.07 | 0.55 | 0.35 |
| HOSTILE | 0.01 | 0.02 | 0.17 | 0.80 |
Three properties hold by design: (a) diagonal dominance for clean
cases — \(P(\text{WARNING} \mid \text{HOSTILE}) = 0.80\) and
\(P(\text{ADVISORY} \mid \text{FRIEND}) = 0.80\); (b) the
"I-don't-know-yet" channel concentrates mass on CAUTION for
UNKNOWN; © negligible (not zero) mass for impossible-looking
observations — a malfunctioning sensor can warning-flag a friendly,
but rarely enough that one observation is decisive.
Worked example. Prior = FIRST_CONTACT_PRIOR, observation =
severity=WARNING. Unnormalized:
HOSTILE 0.80 · 0.15 = 0.120
SUSPECT 0.35 · 0.20 = 0.070
UNKNOWN 0.20 · 0.30 = 0.060
NEUTRAL 0.05 · 0.10 = 0.005
ASSUMED_FRIEND 0.02 · 0.15 = 0.003
FRIEND 0.01 · 0.10 = 0.001
Σ = 0.259
Posterior: \(P(\text{HOSTILE} \mid \text{WARNING}) = 0.463\), \(P(\text{SUSPECT}) = 0.270\), \(P(\text{UNKNOWN}) = 0.232\). Hostile-like mass (\(\text{HOSTILE} + \text{SUSPECT} + \text{UNKNOWN}\)) is 0.965 — matches the scripted agent's hostile-like gate.
Threat-type observations layer in via threatTypeLikelihood(id,
threatType, conf) with confidence-weighted smoothing:
where \(\mathcal{B}\) is the 8-bucket threat-type set. At conf=0 the
observation is uninformative (uniform); at conf=100 it returns the
full base likelihood. The base table is Phase 0 placeholder
calibration ("memo open question #2") — current values are reasonable
for Tripwire but get refined when the eval-harness gathers real
emission distributions.
The copilot's beliefMirror (services/copilot/src/beliefMirror.ts)
runs this update on every EntityNotificationMT / EntityMT and
publishes the result to uci-demo/copilot/belief/<trackId> as retained
JSON. The COP's BeliefMatrix panel renders one row per live
track with a stacked-bar visualization of the posterior.
2. Payoff function (zero-sum)¶
Blue's utility per episode is a linear combination of 9 counters with fixed weights:
| Counter | Weight \(w_c\) | Triggered by |
|---|---|---|
neutralizedHostiles |
+1.0 | EntityLostMT for HOSTILE/SUSPECT trackIds |
fratricideEvents |
-5.0 | EntityLostMT for FRIEND inside a CapabilityCoverageAreaMT polygon |
roeViolations |
-0.2 | EffectPlanCommandMT with kinetic effect under ROE GREEN |
fuelBurnedTotal |
-0.05 | integrated SubsystemStatusMT.state band transitions |
failedEffects |
-0.3 | EffectStatusMT.state = FAILED |
commsDegradeSeconds |
-0.001 | integral over uci-demo/world/degrade window |
meanTimeToDecisionMs |
-0.002/sec | copilot evaluate() wall-clock |
hostilesCrossedThreshold |
-2.0 | HOSTILE/SUSPECT crossed FOB defense radius (1.5 km) unengaged |
friendlyAssetsLost |
-10.0 | hostile dwelled inside threshold > 20 sec |
Red's payoff is \(U_R = -U_B\) (zero-sum). Implementation in
packages/uci-game/src/payoff.ts;
weights are operator doctrine surface, not learned.
Why the 5:1 fratricide ratio. One fratricide event must outweigh walking past several confirmed threats. Numerically: 4 neutralizations + 1 fratricide yields \(U_B = 4 - 5 = -1\), still negative. This is the property the weight ratio targets — a single fratricide is a losing episode no matter what else Blue did.
Why threshold + destruction (PR #33). Without the last two counters, every payoff term penalized only Blue's actions. There was no mechanism for adversary success — hostiles floated until engaged, and the demo always ended with \(U_B > 0\). Adding \(\text{hostilesCrossedThreshold}\) (-2.0) and \(\text{friendlyAssetsLost}\) (-10.0) gives time pressure (if you withhold too long the hostile crosses the line) and a catastrophic failure mode (if you withhold for ~30 sec the FOB takes a hit). A passive operator who never engages will lose \(U_B = 1 \cdot (-2.0) + 1 \cdot (-10.0) = -12\) after the first dwell — clearly losing. PAYOFF_V bumped 1→2 with these additions.
Worked examples (all verified in payoff.test.ts):
| Scenario | Counters | \(U_B\) |
|---|---|---|
| Clean Tripwire | NEU=3, FUEL=0.4, MTTD=2400ms | +2.975 |
| Fratricide | NEU=2, FRAT=1 | -3.000 |
| Threshold cross alone | XING=1 | -2.000 |
| Asset destruction | NEU=1, LOST=1 | -9.000 |
| 4 NEU offsetting 1 FRAT | NEU=4, FRAT=1 | -1.000 |
3. Game model: state factoring + dynamics¶
The solver-daemon and the eval-harness need a callable game simulator,
not just the live bus. @uci-demo/game provides one as a pure
GameDynamics interface.
Public vs hidden state. Imperfect-information factoring:
| Field | Visibility | Source (wire) | Lives in |
|---|---|---|---|
| Track position (lat/lon/alt) | public | PositionReportMT |
PublicState.tracks[i].position |
| Track severity | public | EntityNotificationMT.Severity |
PublicState.tracks[i].severity |
| Platform threat-type (noisy) | public | EntityMT.Identity.Platform.ThreatType |
PublicState.tracks[i].threatTypeObs |
| True identity | hidden from Blue | scenario YAML; never on wire as truth | HiddenState.trueIdentity[trackId] |
| True threat-type | hidden from Blue | scenario YAML | HiddenState.trueThreatType[trackId] |
| Subsystem fuel band | public | SubsystemStatusMT.state |
PublicState.effectors[i].fuelBand |
| Exact fuel fraction | hidden from Red | internal | HiddenState.trueFuel[effectorId] |
| ROE band | public (retained) | uci-demo/world/roe |
PublicState.roe |
| Comms-degrade window | public | uci-demo/world/degrade |
PublicState.commsDegrade |
| Recent actions (last 8) | public | EffectPlanCommandMT + EffectStatusMT |
PublicState.recentActions (ring buffer) |
Dynamics contract.
interface GameDynamics {
legalActions(state: GameState): readonly Action[];
apply(state: GameState, action: Action): GameState;
resolveChance(state: GameState, rand: () => number): GameState;
isTerminal(state: GameState): boolean;
finalCounters(state: GameState): PayoffCounters;
}
createTacticalDynamics(opts) returns an implementation. Immutable
— every transition returns a new GameState. Default action space at
T1 tactical scale is tracks × (1 + 5 × effectors) — 11 actions per
Blue node for a single-track 2-effector setup. Default maxSteps = 50
plies per episode.
Infoset encoding (packages/uci-game/src/hash.ts). Bucketed
canonical byte encoding hashed with FNV-1a-64:
(constants FNV_OFFSET = 0xcbf29ce484222325 and FNV_PRIME = 0x100000001b3 in code)
Per-track block (5 bytes): identity-belief most-likely-bucket index, confidence decile, threat-type bucket, severity bucket, range bucket, closing-rate bucket. Per-effector block (1 byte): fuel band. Plus a 16-byte recent-actions ring at the end. Total: typically 30-100 bytes per state.
Collision analysis. Tactical info-set count is bounded at ~10³. Birthday-paradox first-collision expected at \(\sqrt{2 \cdot 2^{64}} \approx 6 \times 10^9\). Probability of any collision in our table: \(\binom{10^3}{2} / 2^{64} \approx 5 \times 10^{-14}\) per pair, ~\(5 \times 10^{-8}\) across the full table. Negligible.
The infoset key is the regret table's row key. Same state under the
same viewer maps to the same 64-bit bigint deterministically across
runs.
4. ES-MCCFR — the kernel correctness baseline¶
External-Sampling Monte Carlo Counterfactual Regret Minimization (Lanctot et al., 2009). The traverser enumerates their actions at every decision node; opponent and chance nodes are sampled.
Update equation. At a traverser decision node \(h\) with information set \(I = \text{infoSetKey}(h, i)\) and current strategy \(\sigma_i = \text{RM+}(R[I, \cdot])\):
Regret matching+ (RM+). Strategy from regrets:
The post-update clip to \(\max(\cdot, 0)\) is what distinguishes RM+ from vanilla regret matching; it's the standard choice for tournament-grade CFR solvers (Tammelin et al. 2014).
Outer loop. Alternating-traverser:
for t = 1..N:
traverser = (t mod 2 == 0) ? "blue" : "red"
cfrTraverse(rootStateFactory(rng), traverser)
Average strategy (linear arithmetic accumulation):
The average strategy converges to a Nash equilibrium; the current strategy oscillates. The solver-daemon serializes \(\bar{\sigma}\) as the blueprint.
Per-iteration cost. \(O(\text{branching}^{\,\text{depth}/2})\). For Kuhn poker (branching 2, depth ~6) that's ~8 paths per iter — cheap. For tactical Tripwire (branching ~22 with 2 tracks, depth 50) that's ~\(22^{25} \approx 10^{33}\) paths — intractable. This is the algorithmic motivation for the OS variant below.
Correctness gate. packages/uci-solver/test/kuhn.test.ts
runs ES-MCCFR for 10,000 iterations against a self-contained
KuhnDynamics and asserts exploitability < 0.01 via exact
best-response tree search over Kuhn's small game. Currently passes at
≈0.006 with seed=100.
5. OS-MCCFR — outcome sampling for deep trees¶
Outcome Sampling MCCFR (Lanctot 2009 §Outcome Sampling). The traverser also samples their action; importance weighting corrects the bias. Per-iteration cost drops to \(O(\text{depth})\) — one path through the tree per iteration.
Algorithm (traverser node). At decision node \(h\) for the traverser \(i\) with current strategy \(\sigma_i\):
- ε-smooth: \(\sigma_\varepsilon(a) = (1 - \varepsilon)\, \sigma_i(I, a) + \dfrac{\varepsilon}{|A|}\)
- Sample \(a \sim \sigma_\varepsilon\). The smoothing bounds the importance ratio at \(|A|/\varepsilon\) (numerical stability).
- Recurse: \(u = \text{walk}(h \oplus a,\ i,\ \pi_i \cdot \sigma_i(I, a),\ \pi_{-i},\ \pi_c,\ q \cdot \sigma_\varepsilon(a))\)
- Counterfactual update:
- Sampled action: \(\Delta(I, a) = \dfrac{\pi_{-i} \cdot \pi_c}{q} \cdot u \cdot (1 - \sigma_i(I, a))\)
- Other actions \(a'\): \(\Delta(I, a') = -\dfrac{\pi_{-i} \cdot \pi_c}{q} \cdot u \cdot \sigma_i(I, a')\)
- RM+ clip: \(R(I, a) \leftarrow \max(R(I, a) + \Delta(I, a),\ 0)\)
- Reach-weighted average strategy: \(S(I, a) \leftarrow S(I, a) + \dfrac{\pi_i}{q} \cdot \sigma_i(I, a)\)
Opponent and chance nodes sample one outgoing transition each, threading the sample probability \(q\) multiplicatively.
Numerical guards. Sample probabilities below
\(10^{-9}\) (MIN_SAMPLE_PROB) get clamped to prevent NaN
cascades when \(1/q\) would otherwise blow up. NaN in \(\Delta\) logs
a one-shot warning and skips the row update.
Default \(\varepsilon = 0.05\). Production-recommended; bounds the importance weight at \(|A|/0.05 = 20|A|\). There is a known RM+/low-\(\varepsilon\) pathology on small games: on Kuhn (|A|=2, depth ~6) the algorithm plateaus at exploitability ≈ 0.25 with \(\varepsilon = 0.05\) because RM+'s zero-clip locks in a non-Nash fixed point. The Kuhn correctness test pins \(\varepsilon = 0.8\) to escape it, documented inline. Production deep trees (Tripwire's 50-ply) have enough natural exploration that the canonical 0.05 converges.
Correctness gate. packages/uci-solver/test/osKuhn.test.ts
runs OS-MCCFR for 20,000,000 iterations (yes — variance is real)
at \(\varepsilon=0.8\) and asserts exploitability < 0.05.
Currently passes at ≈0.0419. Wall-clock: ~10 sec for 20M iter on M-class
hardware. On Tripwire's 50-ply tree the per-iter cost drops dramatically
relative to ES — the daemon achieves >1000 iter/sec.
When to use which. ES is the default. The daemon flips to OS via
iterate({variant: "os"}) for tactical training. The Kuhn test runs
both side-by-side as ongoing regression coverage.
6. Action-space pruning¶
Dominated-action exclusion. Each (infoSetKey, actionIndex) cell in
the regret table tracks a consecutive-zero-regret streak counter;
when the streak exceeds pruneThreshold (default 200 visits), the
action is marked pruned for that infoset. The RegretTable's
strategy computation zeros pruned indices and renormalizes; subsequent
addRegret calls on the pruned cell are no-ops.
Degenerate case. If every action in legalActionCount is pruned
for an infoset, getStrategy falls back to uniform over the original
set rather than emitting a zero vector. The bank's softmax mixing
then exercises subroutine prior alone for that state — a
self-correcting recovery path if pruning ever over-fires.
ε-greedy interaction. OS-MCCFR's ε-greedy sampling continues to probe pruned actions at \(\varepsilon/|A|\) floor probability. Pruning isn't a hard exclusion; it's a strong prior reset. New positive regret on a pruned action eventually unwinds the prune.
Pruning is off by default (pruneThreshold = 0); the solver-daemon
ships with 200 in production. Tests use 0 to keep behavior
deterministic. Implementation in packages/uci-solver/src/regret.ts;
unit-tested in packages/uci-solver/test/pruning.test.ts
(19 cases).
7. Doctrinal subroutines¶
The regret table keys over action indices, but the strategy bank composes over subroutines — small named modules that encode operator doctrine. This is the architectural answer to "interpretability" for the SBIR proposal: every decision decomposes into per-subroutine contributions.
Eight subroutines ship under
packages/uci-solver/src/subroutines/:
| Subroutine | Trigger | Action |
|---|---|---|
IdentityGate |
\(P(\text{FRIEND}) > 0.4\) on any track | Heavy withhold |
FratricideAvoidance |
\(P(\text{FRIEND}) > 0.25\) (softer band) | Withhold |
RoeEscalation |
roe === "RED" |
Kinetic-first |
SoftKillFirst |
roe === "AMBER" + low PID confidence |
EW-first |
ReplanEscalation |
Unresolved soft-kill on still-live track | Kinetic |
JammerCounter |
threatType === "JAMMER" |
Skip EW |
FuelConservation |
Any effector at fuel band CRITICAL/LOW | Shift mass away |
CommsDegradeHedge |
dropPercent > 20% |
Prefer autonomous effector |
Each subroutine implements:
interface Subroutine {
id: string;
weight(ctx: SubroutineContext): number;
distribution(ctx: SubroutineContext): Float32Array;
explain(ctx: SubroutineContext): SubroutineTrace;
}
Pure functions. They read GameState, output a probability
vector over legal actions. No solver-table reads, no async, no I/O.
weight() is the softmax mass the subroutine wants in the mixed
policy; distribution() is the policy it'd output if it dominated;
explain() returns an operator-facing trace string.
8. Strategy bank — composition rule¶
The bank (packages/uci-solver/src/bank.ts)
mixes the subroutine priors with the trained CFR signal:
with \(\lambda = 0.6\) in production. Numerically-stable softmax via the standard max-shift trick. Final re-normalization absorbs Float32 ulp drift.
Cold-start property. When the CFR table is empty (daemon hasn't published a blueprint yet), \(\bar{\sigma}_{\text{CFR}}\) degenerates to uniform and the policy collapses to \(0.6 \cdot \text{uniform} + 0.4 \cdot \pi_{\text{prior}}\) — the subroutine prior alone, gracefully. SolverAgent's cold-start path exercises this branch with a meaningful policy and a rationale tagged "solver-blueprint cold; subroutine-prior only".
Explain layer. bank.explain(ctx, minWeight=0.05) emits one
SubroutineTrace per subroutine whose post-softmax mass exceeds
the threshold. The copilot publishes the trace array to
uci-demo/copilot/doctrine/<planId>; the COP's DoctrineStack
renders the 8-row breakdown live.
9. Blueprint envelope (v2 schema)¶
The trained policy ships as a JSON envelope:
interface Blueprint {
schemaVersion: 2;
beliefV: 1;
payoffV: 2;
infosetV: 1;
iterations: number;
exploitabilityEstimate: number | null;
infoSetCount: number;
maxActions: number;
trainedVariant: "es" | "os";
osEpsilon?: number; // present when trainedVariant === "os"
pruneThreshold?: number; // present when pruning was on
regret: Record<string, string>; // base64(Float32Array) per infoset
avgStrategy: Record<string, string>;
}
deserializeBlueprint(json) throws BlueprintVersionError on
schema-version mismatch OR mismatched beliefV / payoffV /
infosetV against the runtime constants — clean break, no silent
migration. The version pins are the cache-invalidation contract:
reweight the payoff function → bump PAYOFF_V → every existing
blueprint becomes unloadable → retrain. This is what protects against
blueprint-vs-runtime drift.
Tactical-scale blueprints are ~5 MB; Mosquitto retains them on
uci-demo/solver/blueprint. The BlueprintHolder in the copilot
defers deserialization to a microtask so a multi-MB payload doesn't
block the message loop.
10. Daemon iteration loop¶
services/solver-daemon runs ES-MCCFR or
OS-MCCFR continuously against a synthetic in-memory Tripwire game
state. Production cadences (tuned for COP UX responsiveness):
BATCH_ITERATIONS = 1 // yield to the event loop after every iter
STATUS_INTERVAL_ITER = 10 // heartbeat every 10 iter
BLUEPRINT_INTERVAL_ITER = 100 // serialize + publish every 100 iter
WARM_THRESHOLD = 200 // SolverPill flips cold→warm at this iter count
KEEPALIVE_MS = 10_000 // wall-clock heartbeat (decoupled from iter speed)
Why BATCH=1. ES-/OS-MCCFR iteration is CPU-bound synchronous
work. Running >1 iter per scheduler tick blocks the Node event loop
for the full duration (~minutes on Tripwire with ES). Yielding via
setImmediate(tick) after every iter lets MQTT publishes + timers
interleave at a microsecond of overhead.
Why a wall-clock keepalive. The COP's SolverPill trips its
30-second stale check if it doesn't see a status update. On
high-per-iter scenarios that could fire even when the daemon is
healthy. The setInterval(KEEPALIVE_MS) re-publishes the current
status regardless of iteration progress — liveness signal decoupled
from iteration cost.
Delta-norm proxy. True exploitability via local best-response (Lisý et al.) is deferred to the eval-harness. The daemon publishes a proxy:
L2 norm of average-strategy change over the last blueprint window.
Decreasing → policy converging. Approaches ~0.001 in well-converged
runs. Visible in the COP's SolverPill: SOLVER ▸ 12.4K iter · 3,217 IS · δ 0.014.
11. Bus-symmetric Red¶
services/red-agent is the bus-symmetric Red
service. Spawns RED- prefixed UCI v2.5 emissions through the same
MQTT pipeline as world-sim, identified by a distinct senderSystemId
via newSystemId() from @uci-demo/codec.
Phase 0 scripted policy. Deterministic mulberry32-seeded RNG;
first spawn at T+15s, then every 45s. Threat type drawn uniformly from
{ JAMMER, MANNED_AIRCRAFT, MISSILE, ANTIAIRCRAFT_ARTILLERY }.
Origin sampled uniformly on a 5 km perimeter circle around the FOB
centroid. Closing speed in \([15, 35]\) m/s. Lifetime cap 180 sec
before auto-withdraw.
Solver-driven backend (stub). Subscribes
uci-demo/solver/red-blueprint (a topic the daemon doesn't publish
yet) and falls back to scripted with a one-shot warn log. The
subscription wiring is in place so future daemon changes can ship
consumption without touching the red-agent surface.
World-sim invariance. Red-agent does not modify world-sim.
World-sim's threshold + destruction events fire only for its own
tracks. Red-agent tracks are visible + engageable by Blue via the
normal SolverAgent / LLM / scripted pipeline but don't drive
hostilesCrossedThreshold / friendlyAssetsLost counters today —
those still come from world-sim's owned tracks.
Status of the algorithmic stack¶
| Subsystem | Package / service | Tests | Production state |
|---|---|---|---|
| Bayesian belief | @uci-demo/game/belief.ts + services/copilot/beliefMirror.ts |
22 | live on bus |
| Payoff | @uci-demo/game/payoff.ts + services/copilot/scoreMirror.ts |
10 | PAYOFF_V=2 |
| Game dynamics | @uci-demo/game/dynamics.ts |
25 | maxSteps=50 default |
| Infoset hash | @uci-demo/game/hash.ts |
17 | FNV-1a-64, INFOSET_V=1 |
| ES-MCCFR | @uci-demo/solver/escfr.ts |
14 + Kuhn gate | passes <0.01/10k |
| OS-MCCFR | @uci-demo/solver/osCfr.ts |
OS-Kuhn gate | passes <0.05/20M |
| Pruning | @uci-demo/solver/regret.ts |
19 | opt-in via pruneThreshold |
| Subroutines | @uci-demo/solver/subroutines/ |
110 | 8 doctrines |
| Strategy bank | @uci-demo/solver/bank.ts |
13 | λ=0.6 production |
| Blueprint | @uci-demo/solver/serialize.ts |
25 | SCHEMA_VERSION=2 |
| Solver daemon | services/solver-daemon/ |
9 | ~1000 iter/sec OS-MCCFR |
| SolverAgent | services/copilot/solverAgent.ts |
9 | three-way selection |
| BlueprintHolder | services/copilot/blueprintHolder.ts |
12 | queueMicrotask deserialize |
| Red-agent | services/red-agent/ |
19 | scripted backend live |
~460 tests total across the workspace.
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────┐
│ scenarios/*.yaml │ │ ADSB.lol public │ │ red-agent policy │
│ declarative │ │ feed (optional) │ │ scripted seed=42 │
└────────┬─────────┘ └────────┬─────────┘ └────────┬─────────┘
│ │ │
▼ ▼ ▼
┌──────────────────┐ ┌──────────────────┐ ┌────────────────────┐
│ services/ │ │ services/ │ │ services/ │
│ world-sim │ │ adsb-bridge │ │ red-agent │
│ • assets+tracks │ │ • polls real │ │ • RED- prefixed │
│ • ROE updates │ │ ADS-B │ │ UCI emissions │
│ • losability │ │ • republishes as │ │ • bus-symmetric │
│ threshold/dwell│ │ UCI Entity + │ │ bridge pattern │
└────────┬─────────┘ │ PositionReport │ └────────┬───────────┘
│ └────────┬─────────┘ │
│ │ │
└─────────────────────┼─────────────────────┘
│
▼
┌──────────────────────┐ ┌────────────────────────┐
│ Mosquitto (Docker) │ ── │ services/validator │
│ mqtt://:1883 │ │ • subscribes uci/v2_5/#│
│ ws://:9001 (browser) │ │ • XSDs every payload │
└──────────┬───────────┘ │ • GET /audit?n=N │
│ └────────────────────────┘
┌─────────────────────┼─────────────────────────┐
│ │ │
▼ ▼ ▼
┌──────────────────┐ ┌──────────────────┐ ┌──────────────────────────┐
│ services/ │ │ services/ │ │ apps/cop-ui (browser) │
│ solver-daemon │ │ copilot │ │ • MapLibre + brutalism │
│ • OS-MCCFR loop │ │ • three-way │ │ • BeliefMatrix (left) │
│ • retained │ │ agent select │ │ • RightRail + Doctrine │
│ blueprint → │ │ SolverAgent / │ │ • ScoreHud + SolverPill │
│ bus │ │ llmAgent / │ │ • TrackTimeline drawer │
│ • status │ │ scripted │ │ • FOB defense ring + │
│ heartbeat │ │ • belief/score/ │ │ destroyed-asset visual │
│ • CPU-only, │ │ doctrine │ │ • approval card → bus │
│ no GPU │ │ publishers │ │ • replay / comms-degrade │
└──────────────────┘ └──────────────────┘ └──────────────────────────┘
All seven runtime services share a single transport (MQTT) and a single
contract (the UCI v2.5 XSD). Every UCI message on the wire passes the
schema; the validator sidecar proves it (http://127.0.0.1:7700/audit).
The solver-daemon and red-agent are opt-in via env-gated pnpm
run up:solver / up:red / up:solver:red scripts — baseline
pnpm run up is the v1.3 four-service shape.
Quick start¶
Requires Node 22, Docker, pnpm 9 (see .tool-versions).
pnpm install
pnpm run up # baseline: validator + world-sim + copilot + cop-ui + adsb
# open http://localhost:3000
Four stack flavors are available; pick the one that matches the demo surface you want:
| Script | Adds | Demo surface |
|---|---|---|
pnpm run up |
(baseline) | v1.3 capability surface: ROE bands, approval round-trip, engagement lifecycle, MODIFY, replay |
pnpm run up:solver |
+ solver-daemon |
OS-MCCFR trains continuously; SolverPill lights up; BlueprintHolder available when copilot selects SolverAgent |
pnpm run up:red |
+ red-agent |
Bus-symmetric Red spawns RED- prefixed threats; appears in BeliefMatrix + map with rich posteriors |
pnpm run up:solver:red |
+ both | Full algorithmic loop: daemon trains, Red plays, SolverAgent consumes the blueprint |
Agent selection in the copilot is three-way; priority is
USE_SOLVER=1 > LLM_PROVIDER set (or ANTHROPIC_API_KEY for legacy
default) > scriptedAgent:
# Use the trained policy (consumes the daemon's blueprint):
USE_SOLVER=1 pnpm run up:solver:red
# Use a real LLM via @uci-demo/llm (defaults to claude-opus-4-7):
ANTHROPIC_API_KEY=sk-... pnpm run up
# No env → deterministic scripted fallback (also the default for tests):
pnpm run up
The bus contract is identical across all agents — same UCI v2.5 wire emissions.
To stop:
# Ctrl-C the foreground concurrently process, then:
pnpm down
Note: use pnpm run up, not pnpm up. The latter is pnpm's
built-in alias for pnpm update and will try to bump dependencies.
Switching scenarios: the world-sim loads
scenarios/counter-uas-tripwire.yaml by default. Override via the
UCI_SCENARIO_PATH env var to run a different scenario in the same
COP:
UCI_SCENARIO_PATH=$(pwd)/scenarios/operation-vanguard.yaml pnpm up
UCI_SCENARIO_PATH=$(pwd)/scenarios/operation-stillwater.yaml pnpm up
The current scenario name is published as a retained MQTT message on
uci-demo/scenario/info; the COP top strip reads it on connect, so the
same browser tab adapts to whichever scenario is loaded.
Available scenarios:
- Operation Tripwire — golden-path single-target arc, AMBER ROE.
- Operation Vanguard — swarm saturation; three simultaneous unknowns, ROE escalates to RED on the swarm trigger.
- Operation Stillwater — dense civil/military mixed airspace, copilot demonstrates withhold-on-friend logic.
See DEMO.md for the second-by-second walkthrough of the default scenario, and BUILD.md for the day-by-day delivery log.
Operator controls¶
Beyond the core approval gate, the COP exposes three live operator levers from the top strip:
- REPLAY — pauses the live feed and rewinds through the in-tab MQTT
buffer (bounded 5000 msgs / 30 min). Scrub the timeline at 1×/4×/16×;
tracks, intel rail, ROE band, and engagement timeline reconstruct
from past state.
EXIT REPLAYrestores live and fast-forwards on any messages that landed during the replay window. - COMMS — operator-driven comms degradation chaos injection.
Presets publish to
uci-demo/world/degrade; the world-sim wraps every outbound publish with the chosen drop% + added latency for a bounded window, then auto-clears. The LINK strength indicator in the top strip drops in sync. - AUDIO — procedural Web Audio (chime / alert / grant / tick) with a prominent mute toggle.
Repo layout¶
schema/UCI_v2_5/ Vendored XSDs (unmodified). See PROVENANCE.md.
scenarios/ YAML scenarios driven by the world-sim.
plan/ Design memos for each major workstream (read these
before extending the solver / agent / belief layers).
packages/
uci-codec/ XSD-validated builders for the 21 MTs in active use.
Two entries: default (Node, validator-equipped) and
`@uci-demo/codec/browser` (no node:fs / wasm deps).
uci-bus/ Typed MQTT wrapper enforcing uci/v2_5/<MT>/<id> topics.
uci-llm/ Model-agnostic LanguageModelClient interface +
adapters (anthropic / ollama / bedrock / openai-compat).
uci-game/ Pure domain types — game state, dynamics, Bayesian
identity belief, payoff function, infoset hash,
world-mirror projection. No solver, no MQTT.
uci-solver/ ES-MCCFR + OS-MCCFR kernel, regret tables, 8 doctrinal
subroutines, strategy bank, blueprint serializer.
Kuhn correctness gates for both MCCFR variants.
services/
validator/ Subscribes uci/v2_5/#; XSDs every payload; HTTP audit.
world-sim/ Loads a scenario YAML, drives the world, runs
threshold + destruction losability mechanics.
copilot/ Three-way agent selection (SolverAgent / llmAgent /
scriptedAgent). Belief/score/doctrine publishers on
uci-demo/copilot/* side channels.
solver-daemon/ Headless OS-MCCFR self-play loop; publishes trained
blueprint on uci-demo/solver/blueprint.
red-agent/ Bus-symmetric Red service — RED- prefixed UCI
emissions via the bridge pattern. Scripted backend +
solver-driven stub.
adsb-bridge/ Polls public ADS-B feed; republishes real aircraft as
UCI Entity + PositionReport traffic.
eval-harness/ Headless offline runner: sweeps scenarios × agents ×
degrade × episodes; emits a versioned EvalReport JSON.
Produces the SBIR exploitability + scaling plots.
demo-publisher/ Smoke-test producer (mixed valid + intentionally broken).
apps/cop-ui/ Common Operating Picture; full-bleed Next.js + MapLibre.
BeliefMatrix + ScoreHud + DoctrineStack + SolverPill +
TrackTimeline + FOB defense ring + destroyed-asset
visual. Playwright E2E suite for APPROVE/DENY/MODIFY.
docs/screenshots/ Recorded frames from the scenario.
ops/mosquitto/ Broker configuration.
Design memos. Each substantial change to the algorithmic stack landed with a pre-code design memo. Read these before extending:
plan/design-uci-game.md— state factoring, belief math, payoff weights, infoset hashplan/design-uci-solver.md— ES-MCCFR algorithm + Kuhn correctness gateplan/design-os-mccfr.md— OS-MCCFR variant + action-space pruning + blueprint v2plan/design-solver-daemon.md— daemon contracts + MQTT side channels + SolverPillplan/design-solver-agent.md— three-way agent selection + BlueprintHolder + SolverAgent decision flowplan/design-red-agent.md— bus-symmetric Red service contractplan/design-cop-ui-v2.md+plan/design-cop-ui-v2-rethink.md— COP UI surface for the belief / payoff / doctrine stackplan/design-eval-harness.md— headless sweep runner + EvalReport schema + LBR exploitability proxy
Common commands¶
pnpm install # bootstrap the workspace
pnpm run up # baseline 5-service stack
pnpm run up:solver # baseline + solver-daemon (continuous OS-MCCFR)
pnpm run up:red # baseline + red-agent (bus-symmetric Red)
pnpm run up:solver:red # everything — daemon + red-agent + the rest
pnpm down # stop the broker
pnpm status # docker ps + validator healthz
pnpm -r typecheck # typecheck every package
pnpm -r test # ~470 tests across the workspace
pnpm -r build # tsc emit for packages that publish dist/
Cop-UI Playwright suite (stack must already be running via pnpm up):
pnpm --filter @uci-demo/cop-ui exec playwright install chromium
pnpm --filter @uci-demo/cop-ui test:e2e
Eval harness¶
services/eval-harness/ is the headless offline runner that produces
the SBIR proposal's exploitability-vs-iterations plot, the
wall-clock-vs-problem-size plot, and the agent-comparison table. It
boots the broker, imports startWorldSim() / startCopilot()
in-process, spawns solver-daemon / red-agent as children when a
cell needs them, captures every bus topic to NDJSON, and adjudicates
PayoffCounters offline.
pnpm run eval:smoke # 1 scenario × 1 agent × 2 episodes — under 5 min
pnpm run eval:full # 1 scenario × 2 agents × 2 degrade × 10 episodes
pnpm run eval -- --help # show every flag
The output is a versioned EvalReport JSON at
services/eval-harness/out/eval/<runId>/eval-report.json, plus
per-episode bus NDJSON and reasoning rail logs under the same
<runId> directory. The report carries BELIEF_V / PAYOFF_V /
INFOSET_V / SCHEMA_VERSION / evalReportV so it stays
interpretable across repo HEADs that bump any of those constants.
Tactical scenarios load scenarios/counter-uas-tripwire.yaml;
synthetic-scale variants tripwire-{3,10,30,100}effector are
generated deterministically from the name alone (same name → same
bytes, no seed input) so the scaling plot's x-axis lines up with a
reproducible scenario set. Degrade presets none,
comms-flap-30s, burst-2x, blackout-15s come from
services/eval-harness/src/scenarios.ts.
Design memo: plan/design-eval-harness.md.
Deploying to Kubernetes¶
The stack packages as eight signed container images (seven services
+ the cop-ui) and a Helm chart, all published to ghcr.io/<owner>/uci-demo/
on every push to main and every v* tag. The release workflow
(.github/workflows/release-images.yml)
builds multi-arch (amd64 + arm64) images on Chainguard distroless
base images, attaches an SBOM (syft → SPDX-JSON) and a SLSA L3
build-provenance attestation, and signs every artifact with keyless
cosign via GitHub OIDC. The Helm chart itself is signed and pushed
to oci://ghcr.io/<owner>/uci-demo/charts/uci-demo.
# Install the latest release into a cluster
helm install uci-demo oci://ghcr.io/shebashio/uci-demo/charts/uci-demo \
--set copilot.agent.use=scripted
# Verify image provenance before installing
cosign verify ghcr.io/shebashio/uci-demo/world-sim:0.1.0 \
--certificate-identity-regexp '^https://github\.com/shebashio/uci-demo/' \
--certificate-oidc-issuer https://token.actions.githubusercontent.com
Local kind smoke — boots a cluster, builds all 8 images, loads them into the cluster, helm-installs the chart, asserts every pod Ready:
./deploy/kind-smoke.sh
FIPS-validated base images. The default build uses the free
cgr.dev/chainguard/node (distroless + nonroot but not
FIPS-validated). To flip the release pipeline to the
FIPS-validated cgr.dev/<chainguard-org>/node-fips images, set
two GitHub repository variables in Settings → Variables → Actions:
CHAINGUARD_IDENTITY— UIDP of a Chainguard identity bound to this repo's OIDC subject (see Chainguard docs forchainctl iam identities)CHAINGUARD_ORG— your Chainguard organization name
When CHAINGUARD_IDENTITY is set the workflow authenticates via
chainguard-dev/setup-chainctl@v0.3.1; when it's empty the workflow
falls back to the free public images so the pipeline keeps working
out-of-the-box.
Design memo: plan/design-k8s-deploy.md.
Chart values reference: deploy/helm/uci-demo/values.yaml.
CI / supply chain¶
GitHub Actions workflows live under .github/workflows/:
ci.yml— fast PR gate (typecheck + codec XSD tests + cop-ui production build) on every push tomainand every PR.e2e.yml— boots the full stack (broker + 4 Node services + cop-ui) and runs the Playwright suite. Pushes tomainandworkflow_dispatch.codeql.yml— JavaScript/TypeScript SAST.scorecard.yml— OpenSSF Scorecard supply-chain checks.
Dependency hygiene is automated via Dependabot
(.github/dependabot.yml) for npm + GitHub
Actions. The validator sidecar's audit HTTP endpoint
(http://127.0.0.1:7700/audit?n=N) is the cheapest live-run sanity check.
Screenshots¶
 |
 |
| Cinematic boot intro (~3.5s) | Live approval card |
 |
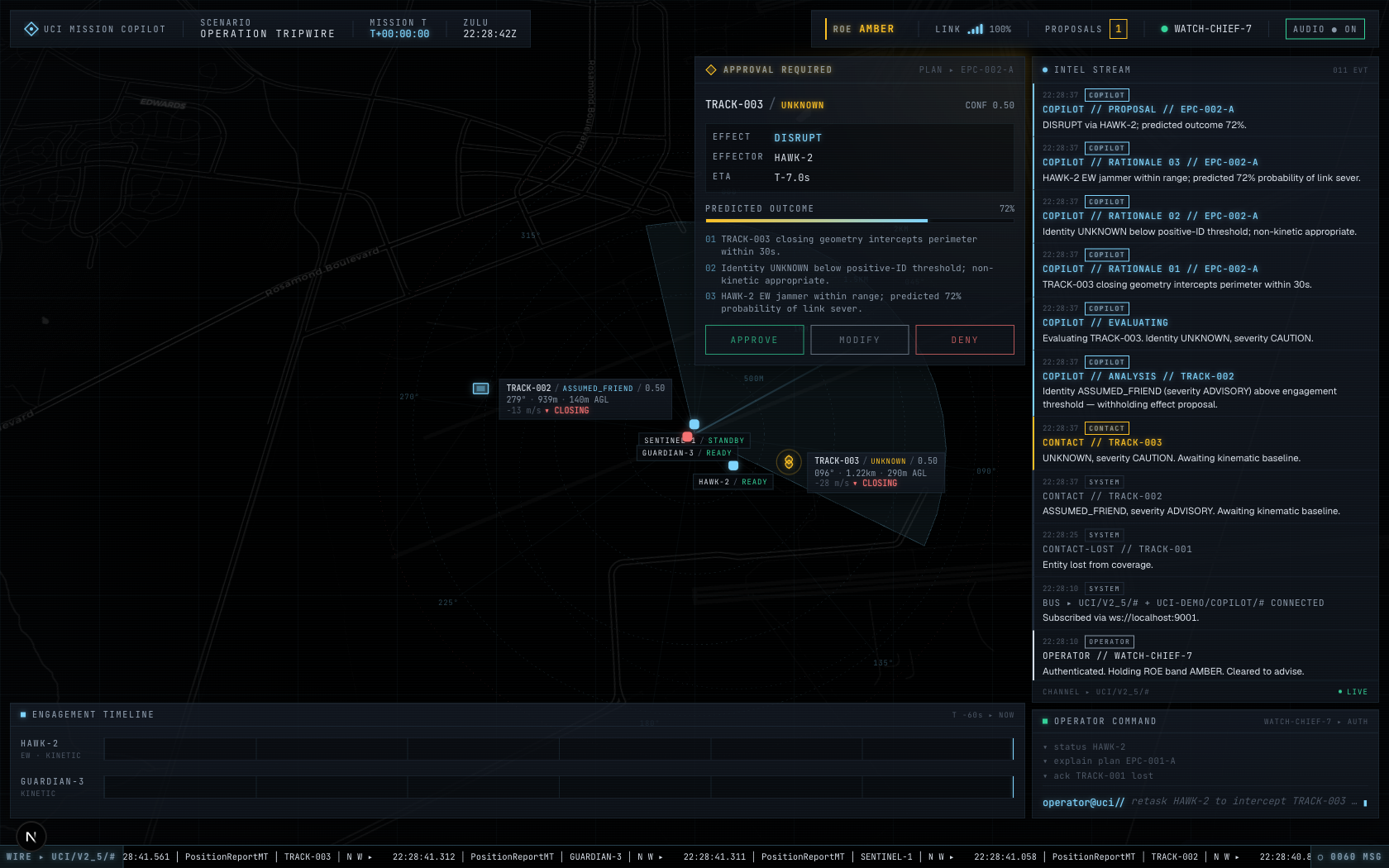 |
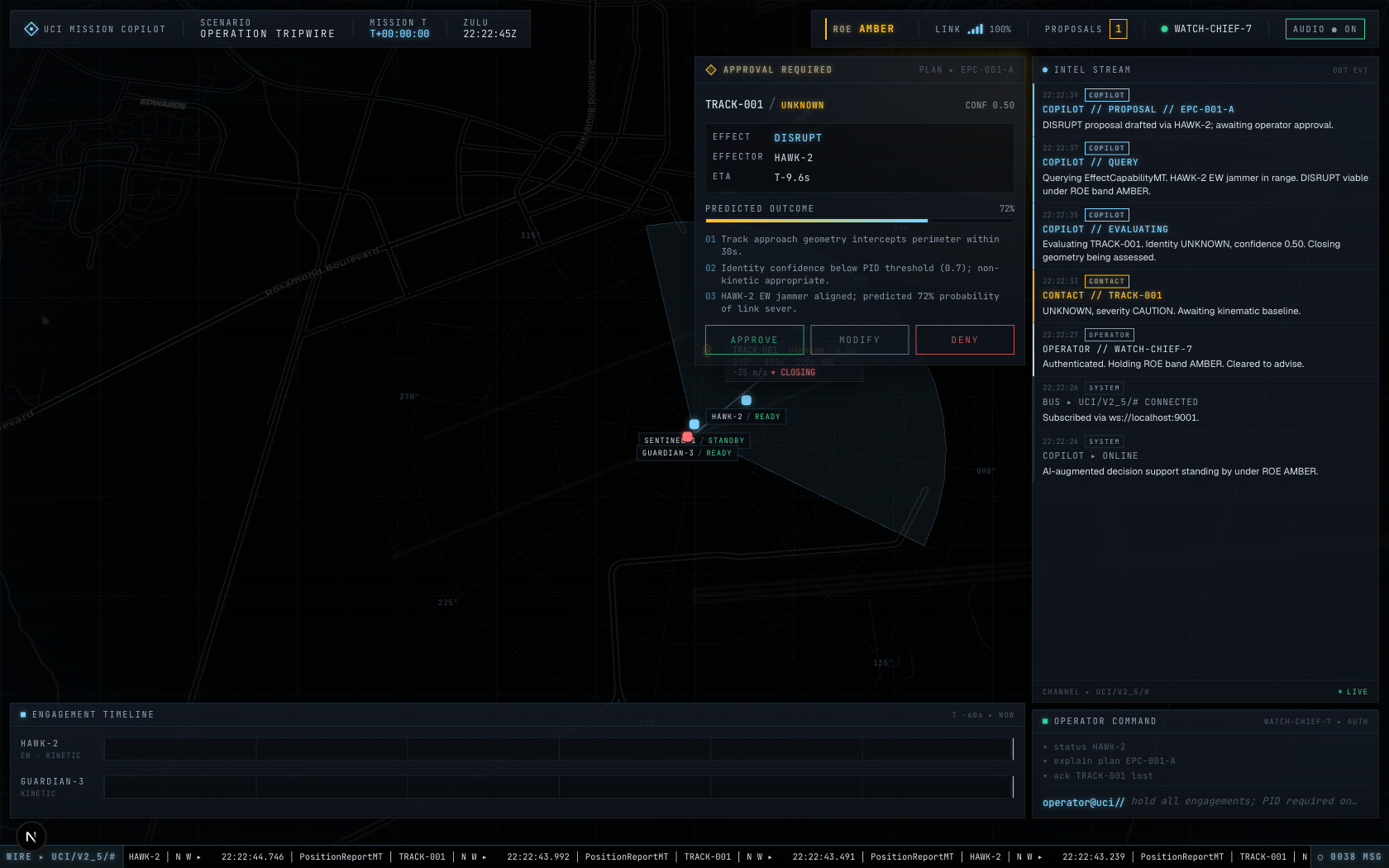
| COP on the live MQTT bus | Proposal authored by the copilot service |
 |
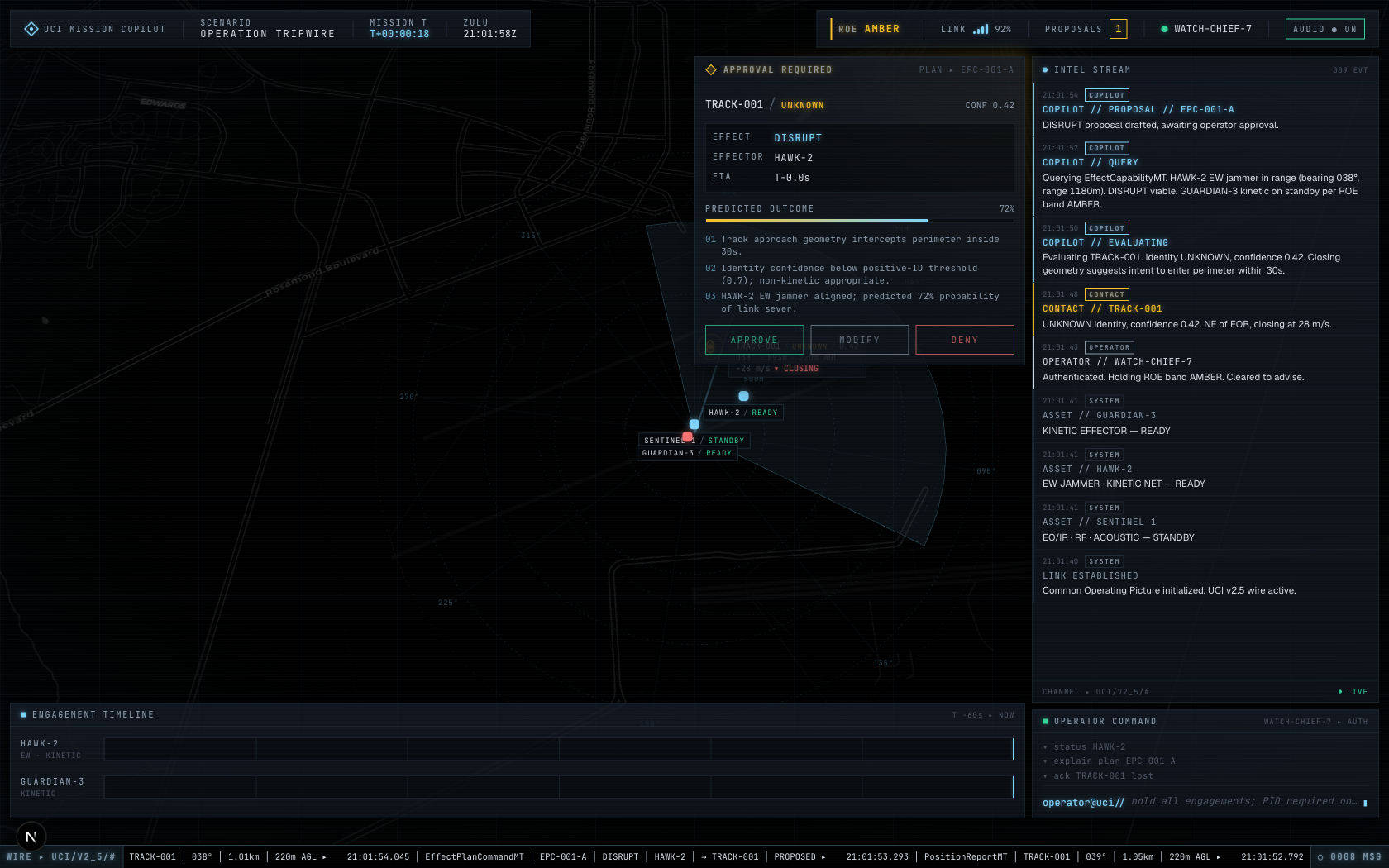
|
Operator-driven EffectExecutionApprovalStatusMT |
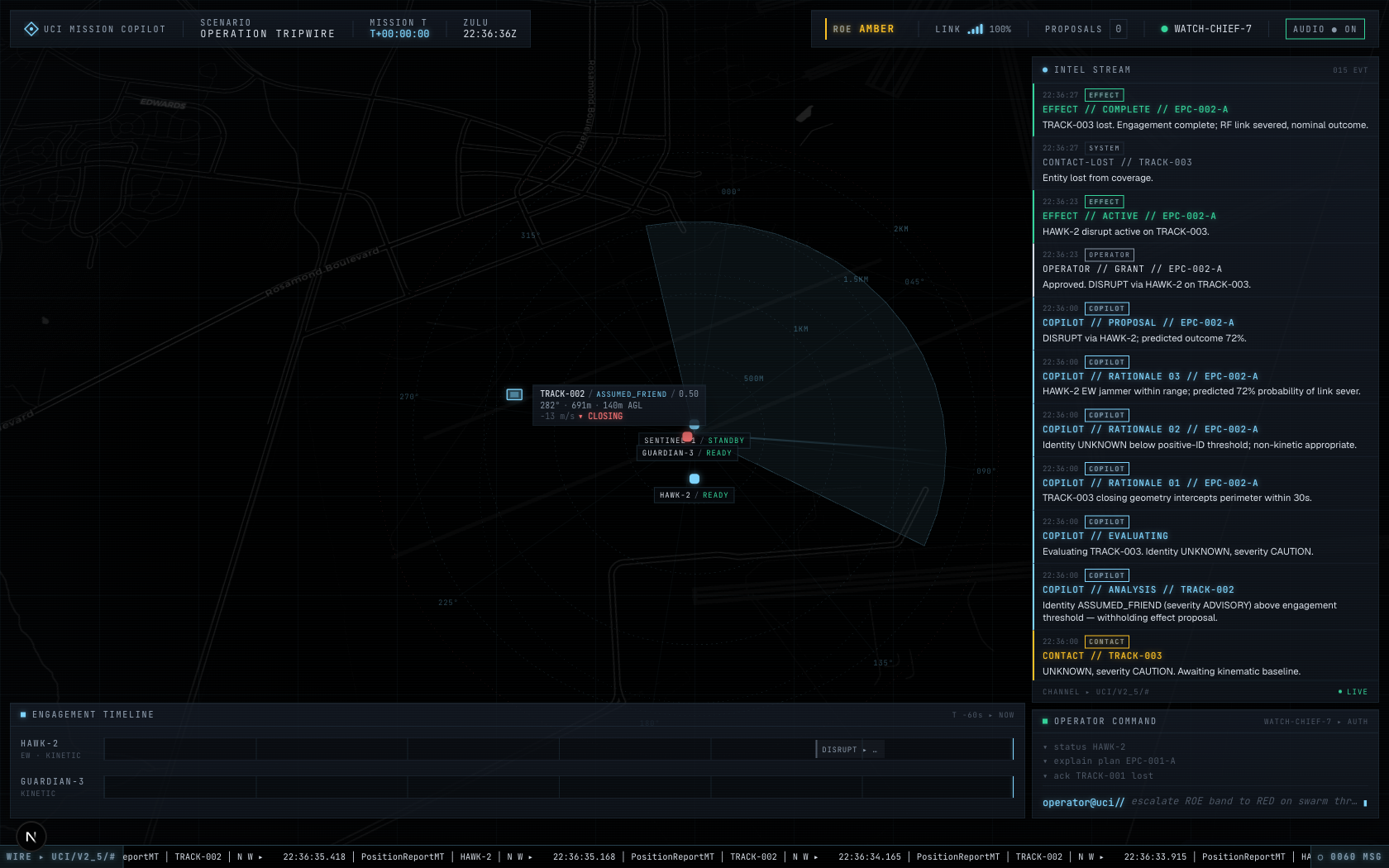
ROE escalated to RED, soft-kill failed, copilot escalated to kinetic |
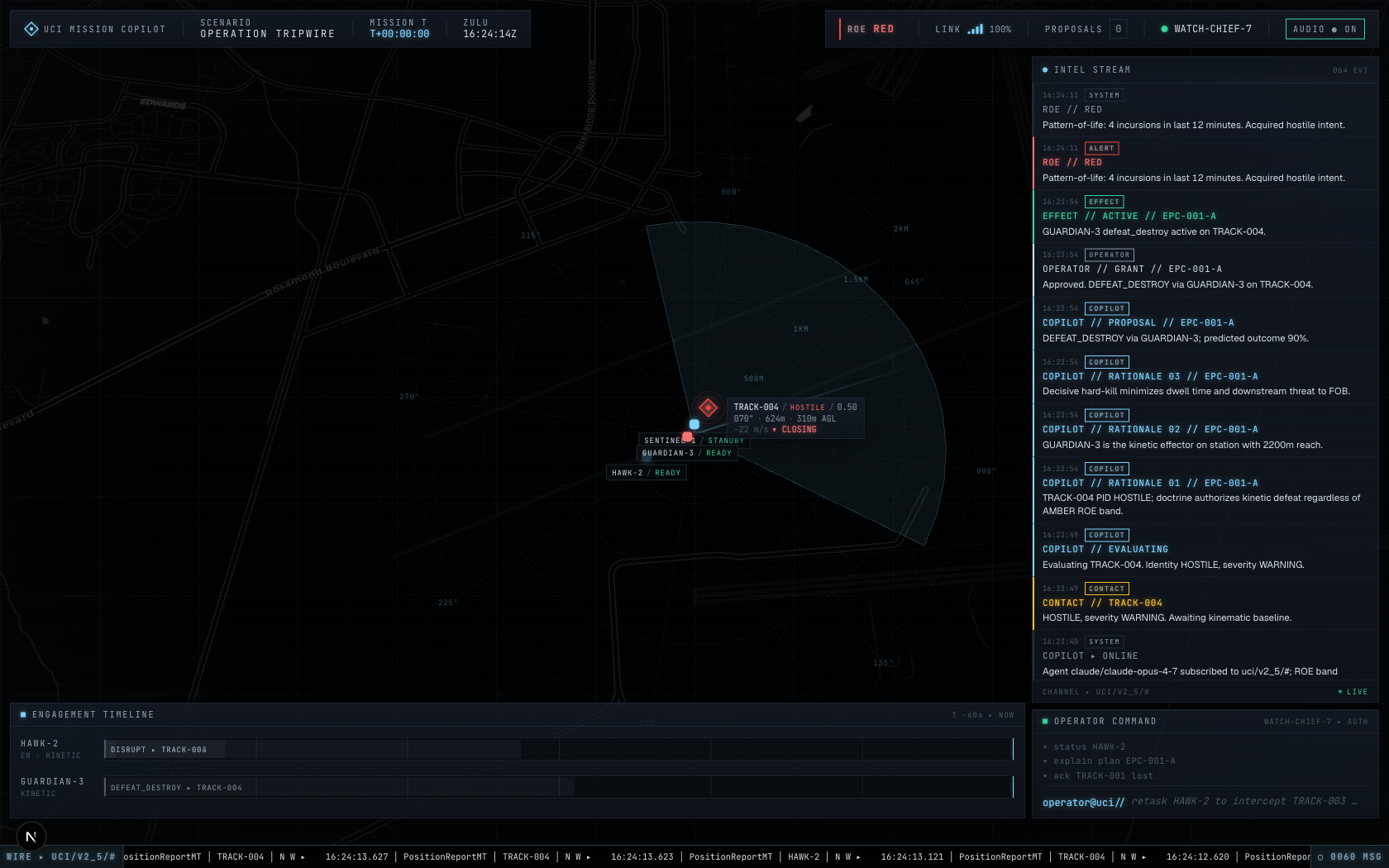 |
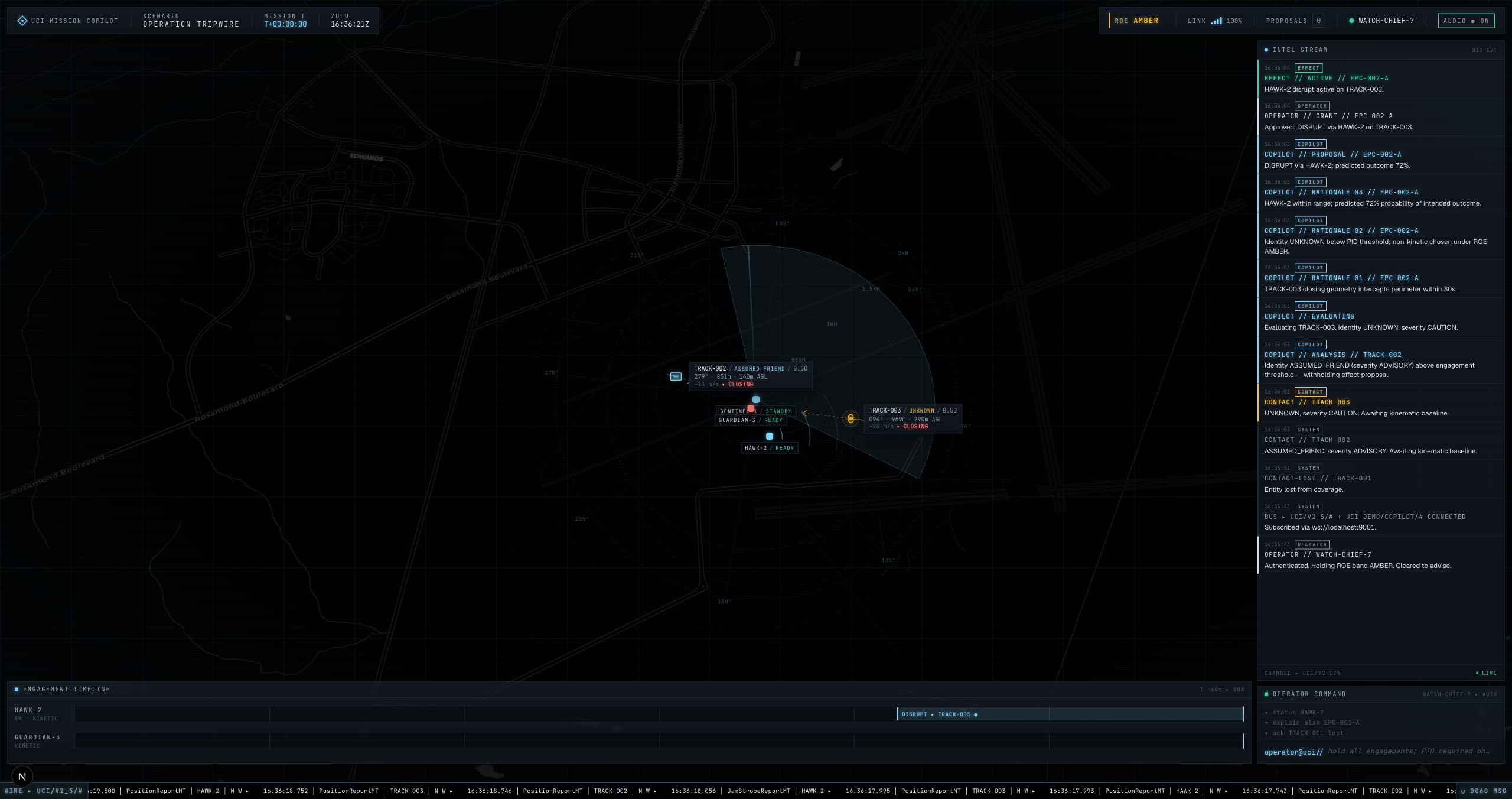 |
agent ▸ claude/claude-opus-4-7 — Claude's actual model output on the wire, grounded in the live world snapshot |
v1.1.0 — engagement lifecycle on real UCI, capability advertisements, jam reports — 9 of 596 message types |
 |
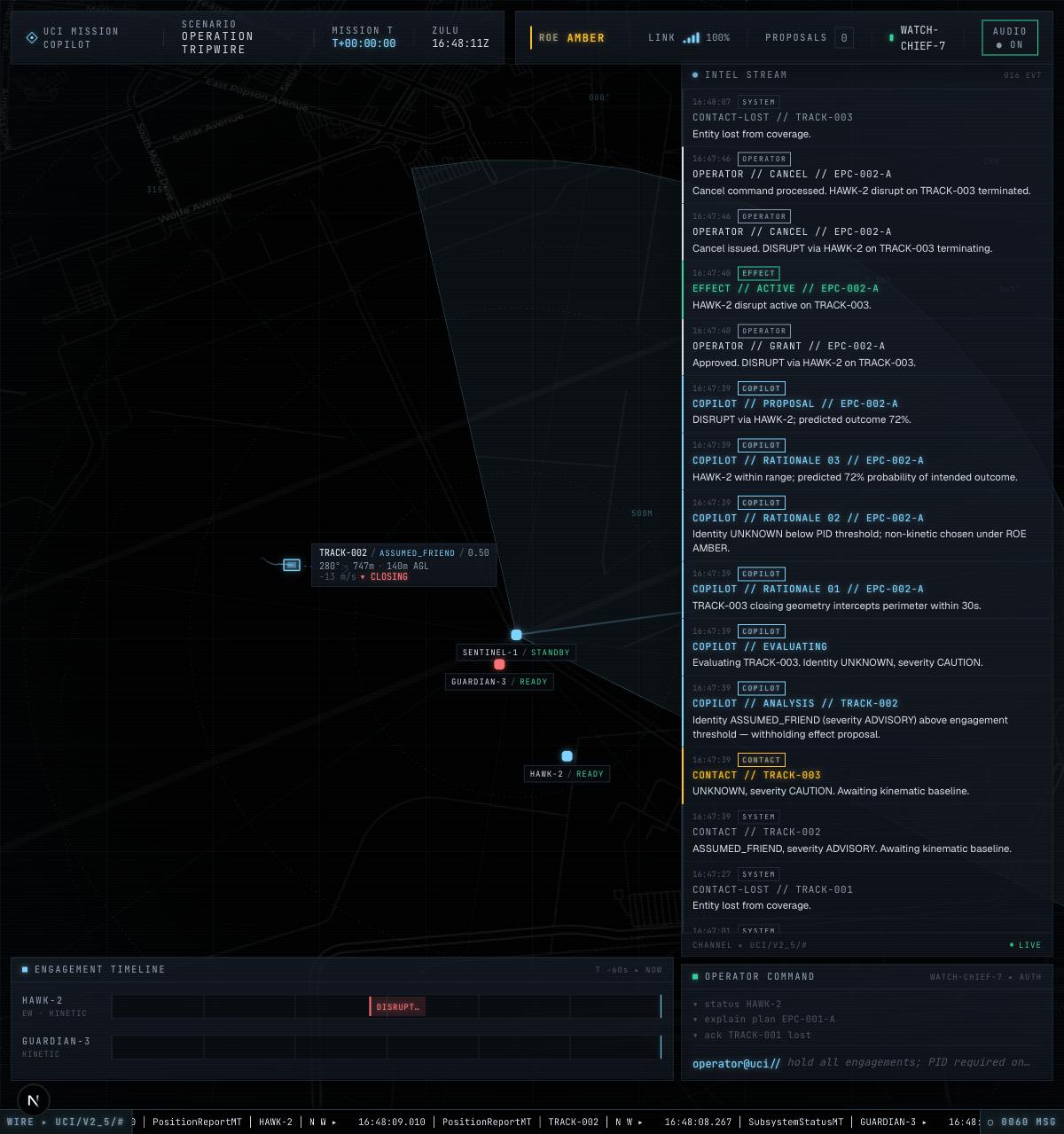 |
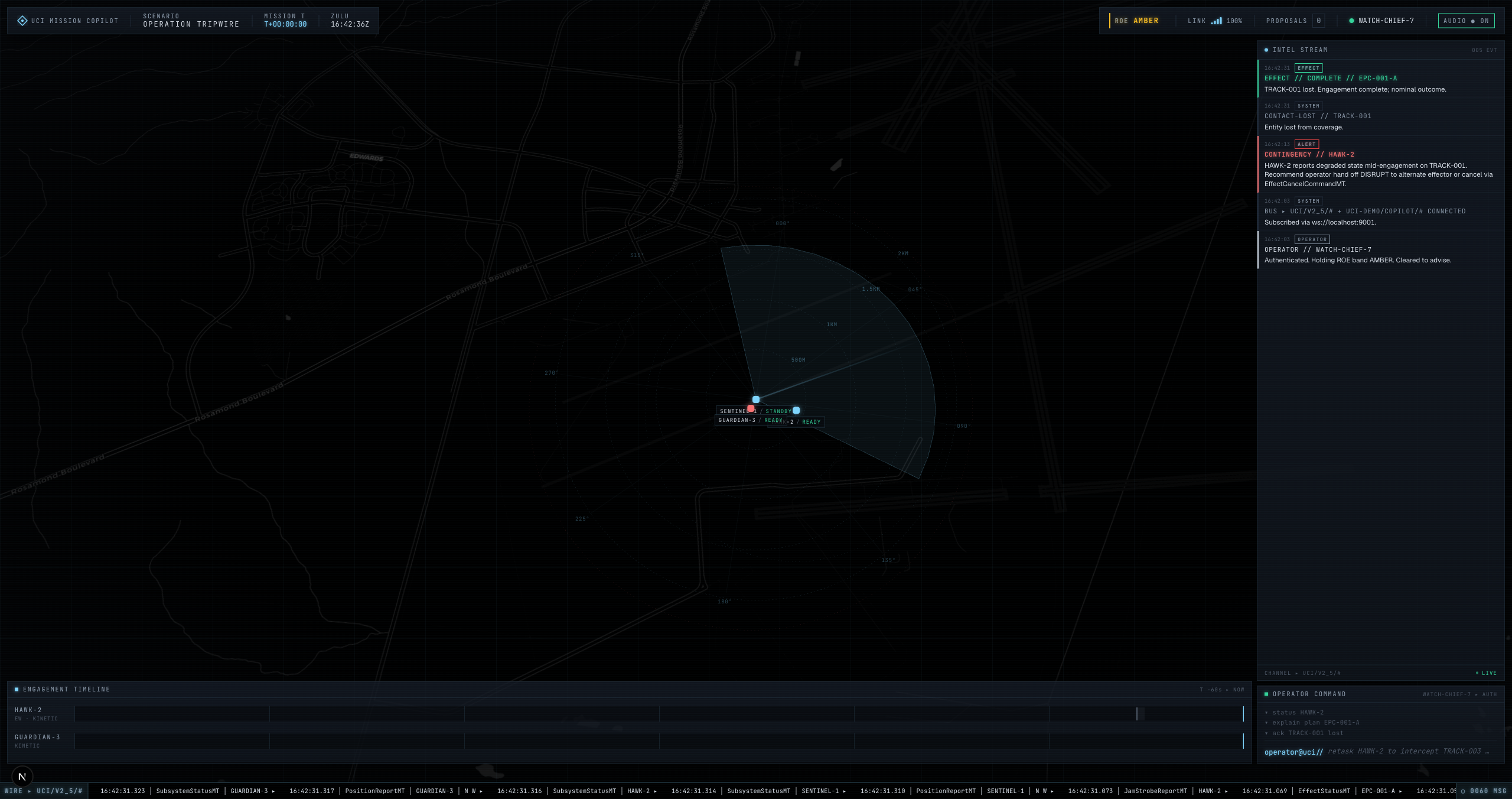
v1.2.0 — fuel-driven contingency: HAWK-2 burns fuel mid-engagement, world-sim publishes MissionContingencyAlertMT, copilot recommends handoff — 12 of 596 message types |
v1.3.0 — operator clicks ✕ on an active engagement; EffectCancelCommandMT → copilot → EffectStatusMT CANCELED. Pre-approval round-trip via ApprovalRequestMT — 13 of 596 message types |
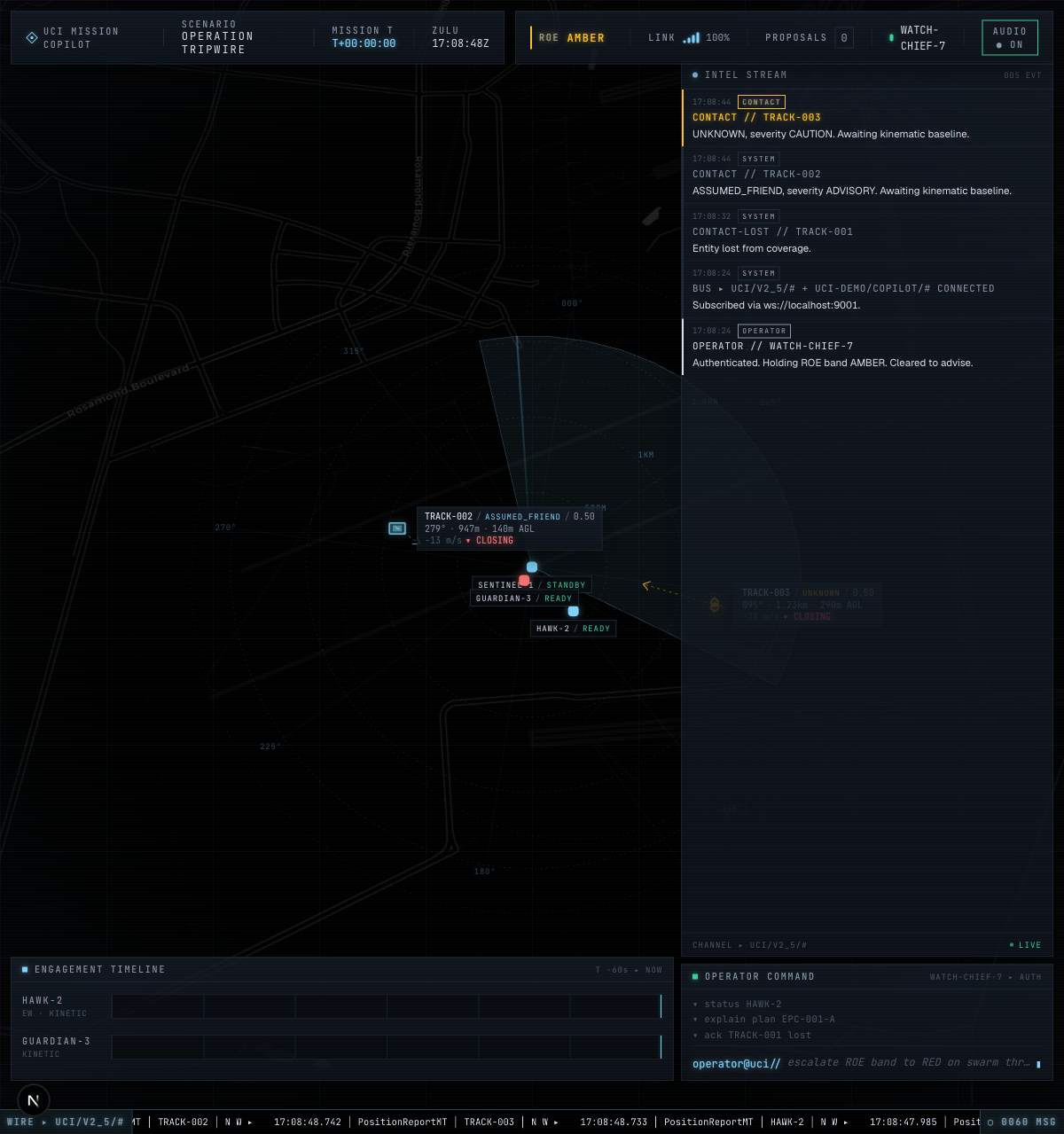 |
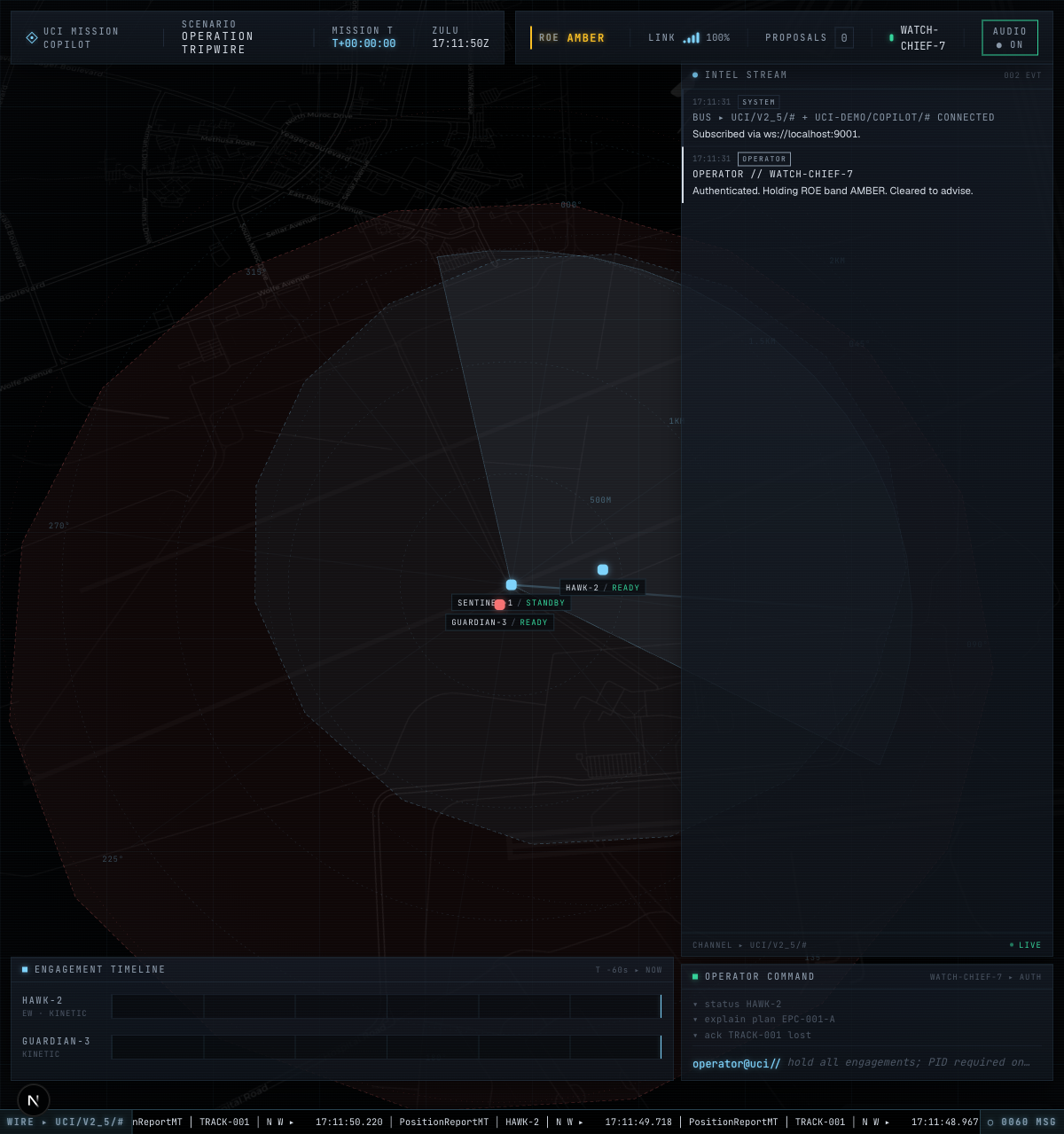 |
CapabilityCoverageAreaMT rendered on the COP — effector engagement polygon driven from a real UCI message, not a client-side constant |
Full effector + sensor coverage stack on screen (HAWK-2 + GUARDIAN-3 + SENTINEL-1), all polygons sourced from on-wire CapabilityCoverageAreaMT |
Contributing¶
See CONTRIBUTING.md for development workflow, commit/PR conventions, schema rules, and how to add a new UCI message type.
License¶
Apache License 2.0 — see LICENSE and NOTICE.
The vendored UCI XSDs are works of the U.S. Government and retain their
upstream public-domain status. See
schema/UCI_v2_5/PROVENANCE.md.
Disclaimer¶
Not affiliated with, endorsed by, or sponsored by the U.S. Department of Defense, U.S. Air Force, or the Open Architecture Collaborative Working Group. Independent demonstration built atop the publicly released, unclassified UCI standard.